



În cazul în care lansările lui Llama 2 și Llama 3 au fost, probabil, unele dintre cele mai importante evenimente din AI pentru anii de lansare respectivi, Llama 4 se simte complet pierdut. Meta a încercat să-și reinventeze formula de modele cu schimbări substanțiale în dimensiune, arhitectură și personalitate, dar lipsește o narațiune coerentă. Meta a căzut în capcana de a aștepta prea mult timp pentru a expedia modelele, așa că baremul actual este imposibil de trecut cu succes.
Urmărește cele mai noi producții video TechRider.ro
- articolul continuă mai jos -
Succesul modelelor deschise de la laboratorul chinezesc de inteligență artificială DeepSeek, care au performanțe egale sau mai bune decât modelele emblematice anterioare Llama de la Meta, a adus în lumina reflectoarelor procesul de dezvoltare a modelelor Llama. Se spune că Meta a activat modul hiperdrive pentru a descifra modul în care DeepSeek a redus costurile de funcționare și implementare a modelelor precum R1 și V3.
Meta spune că Llama 4 este prima sa cohortă de modele care utilizează o arhitectură combinată de experți (MoE), care este mai eficientă din punct de vedere computațional pentru instruire și răspuns la întrebări. Arhitecturile MoE practic descompun sarcinile de procesare a datelor în subsarcini și apoi le delegă unor modele „expert” mai mici, specializate.
Maverick, de exemplu, are 400 de miliarde de parametri în total, dar doar 17 miliarde de parametri activi pentru 128 de „experți”. (Parametrii corespund aproximativ abilităților de rezolvare a problemelor unui model.) Scout are 17 miliarde de parametri activi, 16 experți și 109 miliarde de parametri totali.
Această lansare a venit într-o sâmbătă, ceea ce este cu totul bizar pentru o companie importantă care lansează unul dintre produsele sale de cel mai înalt profil al anului. Consensul a fost că Llama 4 urma să vină la LlamaCon găzduit de Meta la sfârșitul lunii Aprilie.
De fapt, se pare că această lansare ar fi fost grăbită si mai mult, ea fiind programata inițial pentru data de 7 Aprilie conform unor informații din Meta Llama Github.
Mulți, mulți oameni au comentat modul în care comportamentul lui Llama 4 este drastic diferit în LMArena – care a fost rezultatul emblematic evidențiat de Meta la lansare – față de alți furnizori (chiar și atunci când urmează promptul de sistem recomandat de Meta).
Din postarea anunțului de lansare al companiei de pe blog reiese că au folosit un model diferit:
„Llama 4 Maverick oferă cel mai bun raport performanță/cost din clasă, cu o versiune experimentală de chat cu un ELO de 1417 pe LMArena.”
Dubios. Folosirea unui model la acest test, diferit de cel lansat, a dus la concluzia ca Meta a folosit un model AI „tunat special” pentru obținerea de rezultate ridicate in testele țintite. Asta ne aduce aminte de Volkswagen si testele motoarelor pe motorină. Atunci compania germană a trișat altfel, același motor avea un comportament diferit când detecta aparatura de test față de utilizarea normală de zi cu zi.
Aici Meta a folosit 2 modele AI diferita, unul creat special pentru obținerea de scoruri favorabile in teste si altul care sa fie folosite de utilizatori.
Această tactică să nu lanseze modelul pe care l-au folosit pentru a-și crea impulsul major de marketing a provocat o dezamăgire majoră a comunității Meta. Sunt exemple de modele AI deschise care la lansare obțineau scoruri mari în ChatBotArena, dar care dezamăgeau în același timp cu performanța modelului pe abilități importante precum matematica sau generarea de cod software.
Confuzie si nemulțumire a provocat si decizia Meta de a „alege” sa prezinte rezultate de teste fără principalii competitori din piața, cu scopul de a cosmetiza și umfla cât mai mult performanța proprie.
Mai jos avem imaginile in care Meta a ales sa prezinte un test pentru modelul Behemoth, deși acesta încă nu este lansat, motivând ca este încă în training, au eliminat liderul momentului, modelul Gemini 2.5 Pro, dar am alăturat si rezultatele modelului de la Google. Studiind rezultatele putem vedea clar de ce, modelul Behemoth este depășit de Gemini 2.5 Pro.
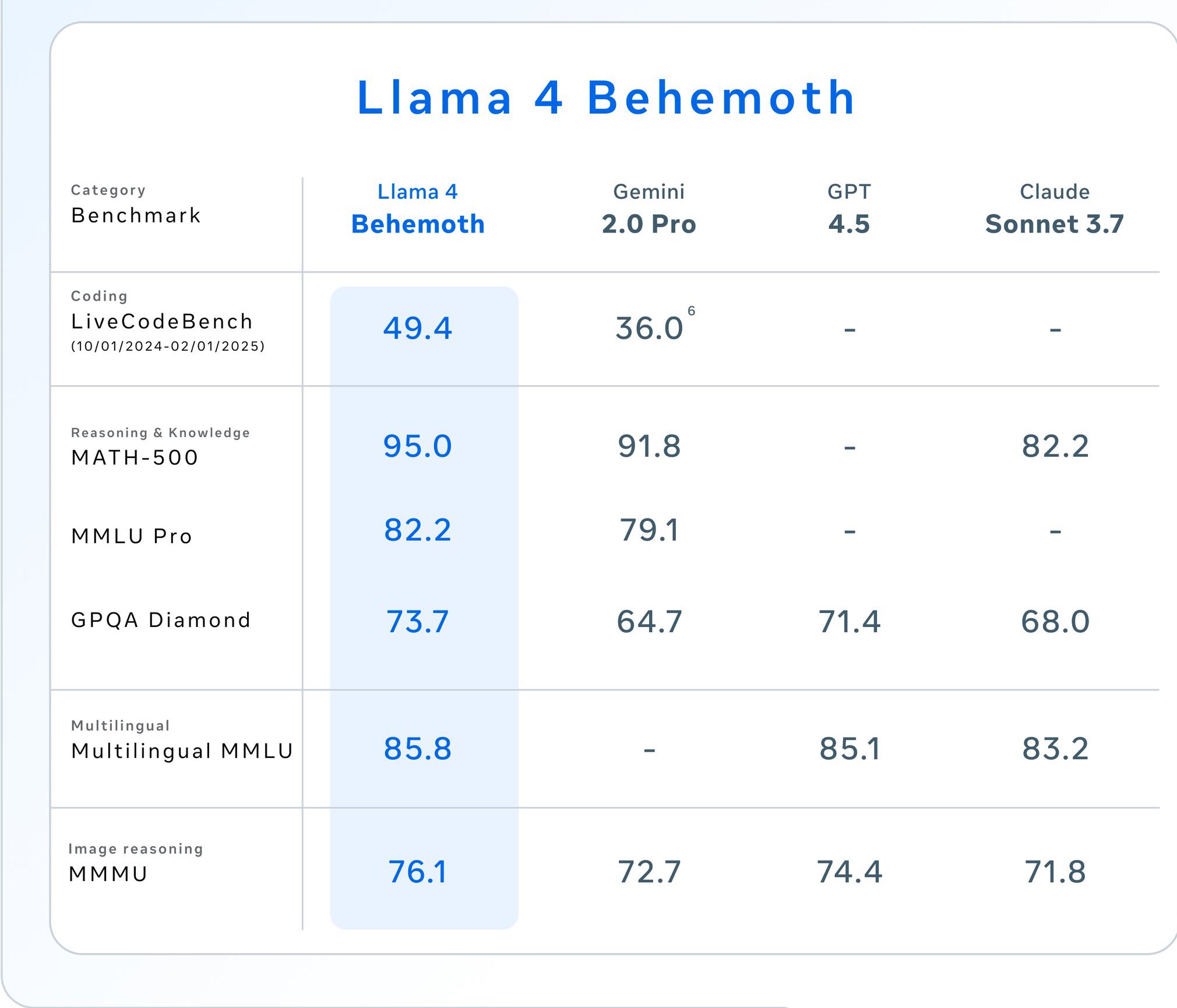
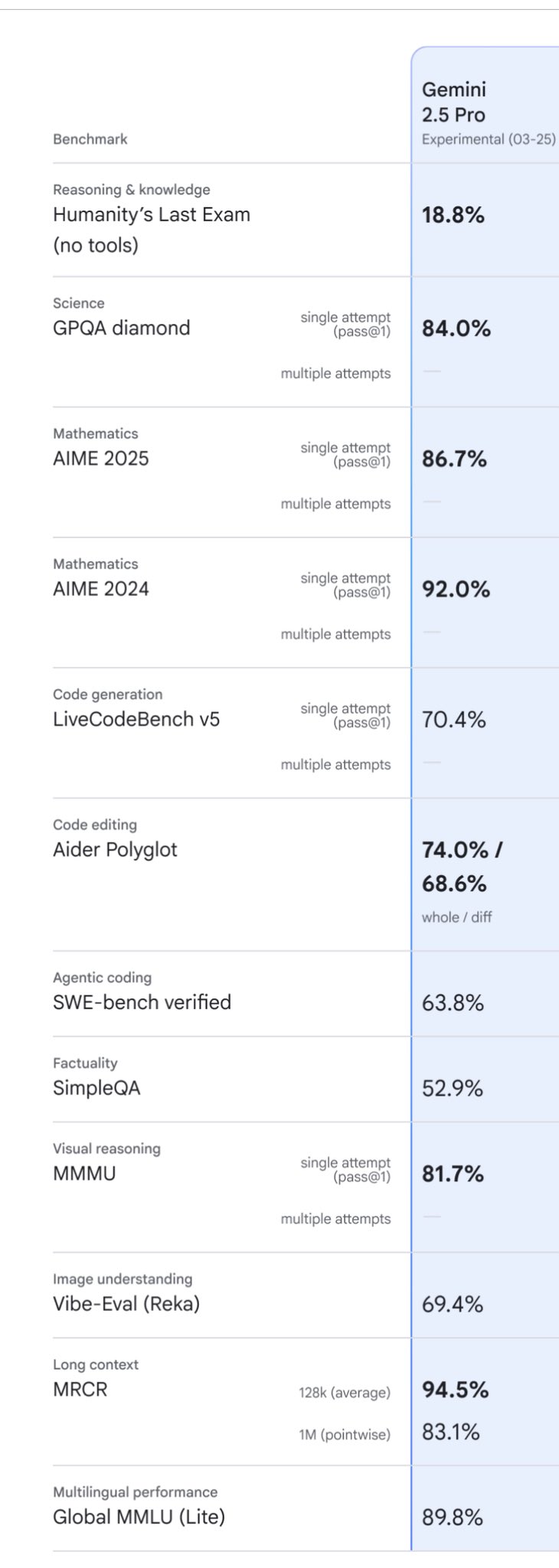
Pe măsură ce alte rezultate ale evaluărilor independente sunt publicate, acestea variază de la mediu la rău și confuz același timp.
Meta a distrus atmosfera de lansare cu acest timing ciudat tactici. Procesul de lansare, calendarul și imaginea de ansamblu ridică mai multe întrebări pentru Meta. Au intrat în panică și au simțit că aceasta era singura lor șansă de a fi de ultimă generație?
Întrebarea aici este: de ce Meta își proiectează modelele în același mod ca și alte laboratoare de frontieră, când publicul lor este format de comunități și companii open-source AI, nu un API care servește afaceri sau un concurent ChatGPT?
Dimensiunile modelului pentru Gemini și ChatGPT sunt la alta scară și sunt luate in calcul decizii nuanțate bazate pe un echilibru între dimensiunea clusterului de antrenament, nevoile de inferență și compromisurile de performanță. Aceste compromisuri sunt foarte diferite pentru modelele deschise, open source, în care utilizatorii nu plătesc inferențe și mulți dintre aceștia nu sunt companii de mari dimensiuni.
Modelul care devine „standardul deschis” open source nu trebuie să fie cel mai bun model general, ci mai degrabă o familie de modele în multe forme și dimensiuni, care este solidă în multe setări diferite de implementare. Qwen 2.5, cu modele la parametrii 0.5B, 1.5B, 3B, 7B, 14B, 32B și 72B, este cel mai apropiat de acest lucru în acest moment. Există, de fapt, mult mai puțină concurență în acest spațiu decât în spațiul în care Meta a ales să intre.
Din punct de vedere istoric, una dintre aceste comunități a fost subreddit LocalLlama, care a coagulat o mare comunitate de utilizatori individuali, care au ales să găzduiască local modele AI. O altă comunitate este cea academică, unde seria de modele din diferite game de dimensiuni este minunată pentru înțelegerea modelelor lingvistice și îmbunătățirea metodelor de antrenare, funcționare si postantrenare. Aceste două grupuri sunt toate sărace în GPU, așa că modelele cu memorie intensivă, cum ar fi acest amestec de experți (MoE) si contextul imens de milioane de tokenuri îi elimină din punct de vede tehnic datorită memoriei limitate.
La toate acestea se adaugă folosirea unei licențe oneroase care face ca toate artefactele care folosesc Llama în acest proces să fie etichetate cu numele „Llama-”, licența Llama, marca „Construit cu Llama” dacă sunt utilizate comercial și necesită restricții de utilizare. În același timp, concurenții lor, adică DeepSeek, și-au lansat cel mai recent model emblematic cu o licență MIT (care nu are aceste restricții).
Tot curioasă este și preocuparea Meta cu biasul, părtinirea politică. Este bine cunoscut faptul că toate modelele lider LLM au avut probleme cu părtinirea –istoric s-au înclinat la stânga când vine vorba de subiectele politice și sociale dezbătute. Acest lucru se datorează tipurilor de date de antrenament disponibile pe internet. „Scopul nostru este de a elimina părtinirea/bias-ul modelelor noastre AI” – afirmă Meta in anunțul de lansare.
Aceste modificări au loc în timp ce administrația actuală de la Casa Albă îi acuză pe chatboții AI că sunt prea „treziți”, „woke” din punct de vedere politic, o Casa Albă care a început un război împotriva politicilor DEI și a celor legate de schimbările climatice.
Acest demers, de dezvoltare de modele AI, ar trebui să fie unul academic în principal și să fie agnostic din punct de vedere politic, însă Meta continuă să facă eforturi de a se „ajusta” la actuala administrație de la Washington.



