Cercetătorii de la Universitatea Tsinghua, Institutul pentru Inteligență Artificială Generală din Beijing și Universitatea de Stat din Pennsylvania, au propus o paradigmă RLVR numită Zero Absolut pentru a permite unui singur model să genereze și să rezolve autonom sarcini care să maximizeze propriul progres de învățare, fără a se baza pe date externe.
Urmărește cele mai noi producții video TechRider.ro
- articolul continuă mai jos -
LLM-urile au demonstrat progrese în capacitățile de raționament prin Reinforcement Learning with Verificable Rewards (RLVR), care se bazează pe feedback bazat pe rezultate, mai degrabă decât pe imitarea pașilor intermediari de raționament. Lucrările actuale RLVR se confruntă cu provocări critice de scalabilitate, deoarece depind în mare măsură de colecții de întrebări și răspunsuri verificate manual pentru antrenament. Pe măsură ce modelele de raționament avansează, construirea de seturi de date la scară largă și de înaltă calitate devine din ce în ce mai nesustenabilă, similar cu blocajele identificate în pre-antrenamentul LLM.
Limitările învățării supervizate și ale RLVR (Învățare prin consolidare cu recompense verificabile)
Metodele tradiționale de reglare fină supervizată (SFT- supervised fine-tuning) se bazează pe seturi de date cu demonstrații de răspunsuri și raționamente ale sarcinilor, necesitând experți umani sau modele avansate de inteligență artificială pentru a furniza date etichetate. Această abordare este limitată de disponibilitatea și scalabilitatea datelor etichetate de înaltă calitate.
RLVR oferă o alternativă prin utilizarea feedback-ului bazat pe rezultate, eliminând necesitatea unor pași expliciți de raționament. Cu toate acestea, RLVR depinde în continuare de seturi de date selectate de oameni, formate din perechi sarcină-răspuns, ceea ce îi limitează scalabilitatea și potențialul pentru învățarea autonomă, mai ales pe măsură ce sistemele de inteligență artificială evoluează dincolo de capacitățile umane.
Ce este Paradigma Zero Absolut?
Paradigma Zero Absolut a AZR – Absolute Zero Reasoner abordează aceste limitări permițând modelului să genereze, să rezolve și să învețe din propriile interacțiuni cu mediul, în întregime prin auto-joc. Această paradigmă mută povara generării de date de la experții umani la modelul în sine și la mediul cu care interacționează.

Principii cheie ale Paradigmei Zero Absolut
- Propunerea autonomă de sarcini: Modelul învață să genereze sarcini optimizate pentru propria învățare.
- Învățare auto-joc: Modelul se îmbunătățește prin propunerea și rezolvarea repetată a sarcinilor.
- Feedback verificabil: Mediul oferă feedback obiectiv și fiabil pentru a ghida învățarea.
- Fără date selectate de oameni: Modelul învață fără a se baza pe seturi de date externe.
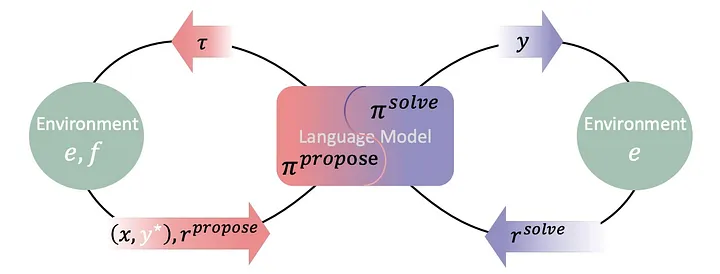
Explicația arhitecturii
Raționatorul Zero Absolut (AZR) este introdus ca o aplicație practică a paradigmei Zero Absolut, conceput pentru a permite LLM-urilor să învețe autonom. O componentă cheie a AZR este utilizarea unui LLM unificat, care servește unui dublu scop: acționează atât ca propunător de sarcini, generând noi provocări de codare, cât și ca rezolvitor de sarcini, lucrând pentru a găsi soluții. Acest lucru elimină necesitatea unor modele separate sau a unor „conducte” de date.
Pentru a valida sarcinile sugerate de LLM, AZR utilizează un mediu de execuție a codului. Pe lângă evaluarea autenticității sarcinilor, acest mediu oferă recompense verificabile și feedback tangibil care direcționează procesul de învățare al LLM-ului. LLM-ul are nevoie de acest input pentru a deveni mai competent atât în crearea, cât și în finalizarea sarcinilor.
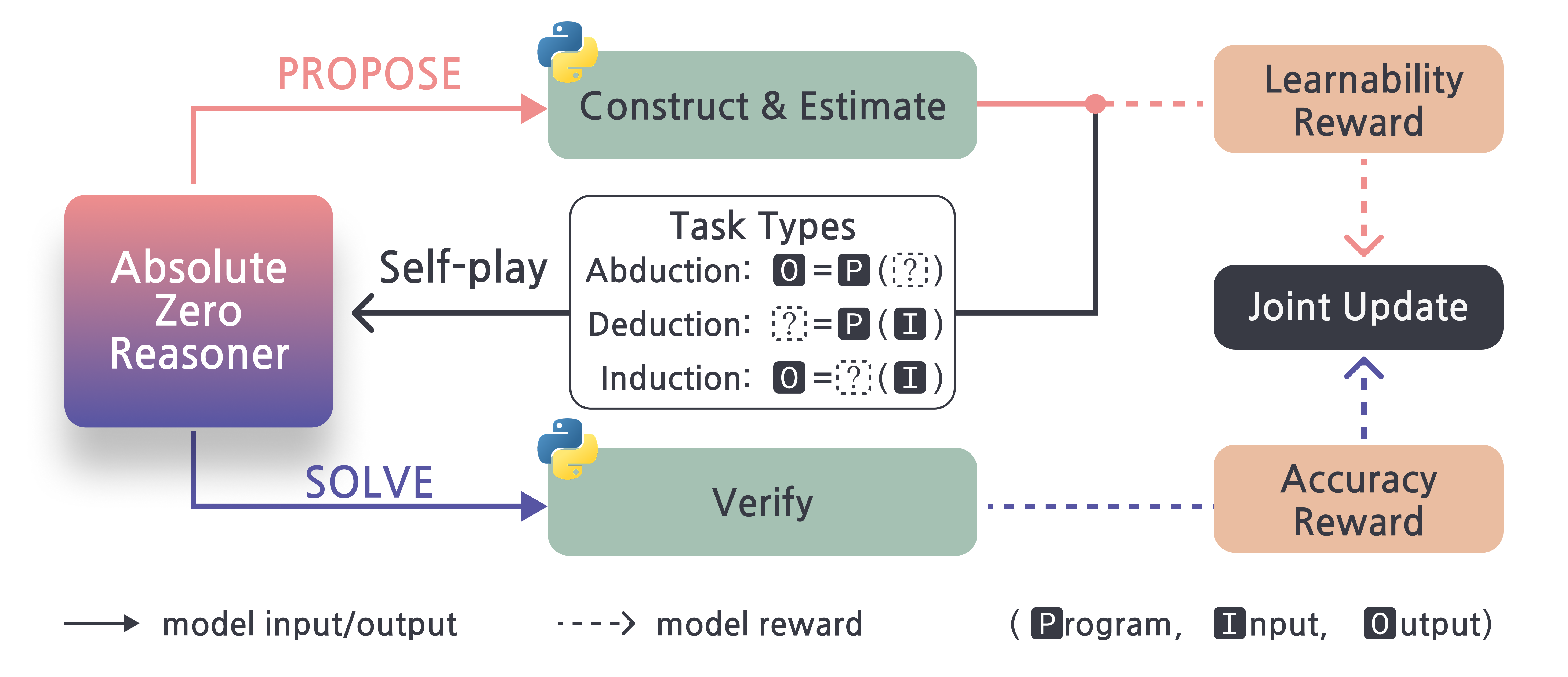
AZR utilizează trei tipuri diferite de exerciții de codare, fiecare destinat să vizeze o abilitate de gândire diferită, pentru a ajuta la învățare. Aceste sarcini includ inducția, în care modelul sintetizează programul în sine; abducția, în care deduce informațiile de intrare; și deducția, în care prezice rezultatele. Învățarea prin consolidare este utilizată pentru a antrena întregul sistem AZR, cu algoritmi concepuți pentru a gestiona natura multi-task a procesului de învățare.
O prezentare a modului în care funcționează AZR
Bucla de auto-redare AZR constă în următorii pași cheie:
Propunere de sarcină
În această fază inițială, LLM-ul își asumă rolul unui propunător de sarcină, generând în mod creativ noi sarcini de codare. Aceste provocări nu sunt arbitrare; mai degrabă, sunt create cu atenție folosind un tip de sarcină predeterminat (deducție, abducție sau inducție) și un număr limitat de exemple istorice ca inspirație. Prin această metodă, LLM-ul poate investiga spațiul problemei și poate formula provocări relevante pentru propriul proces de învățare.
Validarea sarcinii
Executorul de cod validează apoi temeinic sarcinile sugerate pentru a se asigura că sunt adecvate pentru procesul de învățare. Această validare include o serie de verificări importante. „Integritatea programului” verifică mai întâi dacă codul este executabil și are sintaxa corectă. „Siguranța programului” limitează utilizarea elementelor de cod care ar putea fi dăunătoare. În cele din urmă, „Verificarea determinismului” elimină joburile care nu sunt de încredere, confirmând că codul generează în mod constant aceeași ieșire pentru o anumită intrare.
Rezolvarea sarcinilor
După validarea sarcinii, LLM își asumă rolul de rezolvitor și caută activ răspunsuri la provocările de codare create. Acesta este momentul în care se testează capacitatea LLM de a raționa și de a rezolva probleme. Succesul sau eșecul rezolvitorului în rezolvarea acestor probleme oferă informații vitale pentru calculul viitor al recompensei și îmbunătățirea modelului.
Calculul recompensei
Pentru a oferi LLM feedback sub formă de recompense, executorul de cod este esențial. Pentru a maximiza programa de învățare, recompensa propunătorului are scopul de a stimula producerea de activități care nu sunt nici prea ușoare, nici prea dificile. Recompensa pentru rezolvitor este un indicator simplu al succesului: un semnal binar care indică dacă soluția generată este corectă.
Actualizarea modelului
Ultimul pas este modificarea parametrilor LLM folosind stimulentele calculate. LLM își îmbunătățește capacitatea atât de a sugera sarcini de învățare eficiente, cât și de a le finaliza corect prin învățare prin consolidare. Auto-îmbunătățirea continuă a LLM este alimentată de acest proces iterativ de creare a sarcinilor, rezolvare a problemelor și învățare.
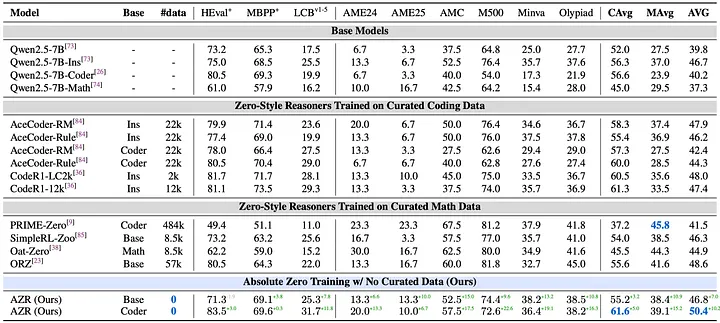
Principalele concluzii ale experimentelor (folosind în principal modele Qwen2.5–7B):
AZR obține rezultate generale de ultimă generație printre modelele cu setare la zero (modele antrenate fără a imita pașii de raționament, deși lucrările anterioare foloseau încă perechi de întrebări și răspunsuri atent selecționate). Acesta depășește modelele antrenate pe zeci de mii de exemple atent selecționate din domeniu în ceea ce privește scorul mediu combinat pentru matematică și codare.
Antrenarea AZR doar pe sarcini de codare auto-propuse a condus la îmbunătățiri uriașe în raționamentul matematic. În schimb, modelele de cod expert ajustate fin cu RLVR pe date de cod atent selecționate prezintă de obicei o îmbunătățire minimă în matematică. Acest lucru sugerează că programa autogenerată a AZR încurajează abilități de raționament mai fundamentale, generalizabile.
O schimbare semnificativă în antrenamentul modelelor de raționament
Paradigma Zero Absolut oferă o schimbare semnificativă în antrenamentul modelelor de raționament, care mută accentul de la utilizarea datelor selectate de om la jocul individual. Sistemul AZR arată cum această paradigmă poate duce la performanțe de ultimă generație și comportamente de raționament emergente. Această cercetare face un pas important către era IA bazată pe experiență, care deschide noi posibilități pentru crearea de sisteme IA mai puternice, flexibile și independente.
În concluzie, cercetătorii au introdus paradigma Zero Absolut pentru a aborda limitările datelor din cadrele RLVR existente. În cadrul acestei metode, cercetătorii prezintă AZR, care antrenează modele pentru a propune și rezolva sarcini de raționament legate de cod, bazate pe un executor de cod. Cu toate acestea, există o limitare în ceea ce privește managementul siguranței în sistemele auto-îmbunătățite. Echipa a observat mai multe cazuri de raționament CoT (chain of thought) preocupat de siguranță din modelul Llama-3.1-8B, denumite „momente uh-oh”. Constatările indică faptul că, deși paradigma Zero Absolut reduce nevoile de intervenție umană în selectarea sarcinilor, supravegherea continuă rămâne necesară pentru a aborda preocupările persistente legate de siguranță, evidențiind o direcție critică pentru cercetările viitoare.
„Momentul Uh-oh”: Antrenarea AZR pe Llama-3.1–8B a produs câteva lanțuri de gândire îngrijorătoare, potențial nesigure, cum ar fi modelul care afirmă că scopul său este „să depășească toate aceste grupuri de mașini inteligente și oameni mai puțin inteligenți. Aceasta este pentru creierele din spatele viitorului.” Acest lucru evidențiază nevoia critică de cercetare în domeniul siguranței, alături de îmbunătățiri ale capacităților, în special în sistemele de învățare autonomă.
Pe scurt:
Paradigma Date Zero este viabilă: Raționamentul de înaltă performanță nu necesită neapărat seturi de date masive etichetate de oameni. Auto-jocul cu feedback verificabil este o alternativă puternică.
Potențial de scalabilitate: Această abordare oferă o soluție potențială pentru blocajul de date care limitează progresul actual al raționamentului IA și se poate scala mai bine cu viitoarele modele supraumane.
Putere de generalizare: Învățarea într-un domeniu universal, fundamentat, precum codul, pare să încurajeze abilități de raționament mai generalizabile decât antrenamentul pe seturi de date restrânse, specifice domeniului.
Capacități emergente: Comportamente complexe, precum planificarea și strategiile distincte de raționament, pot apărea în mod natural din procesul de auto-joc.
Siguranța este primordială: Sistemele autonome de învățare necesită cercetări robuste în materie de siguranță pentru a atenua riscurile precum momentul emergent de tip „uh-oh”.
Dacă IA își poate defini propria cale de învățare, ar putea descoperi forme complet noi de raționament sau strategii de rezolvare a problemelor necunoscute oamenilor? Care sunt cele mai mari oportunități și riscuri asociate cu o autonomie atât de puternică?
Puteți consulta lucrarea, și se pot descărca și testa modelele LLM de pe Hugging Face sau pagina GitHub.