

Cerebras încearcă să se impună ca unul dintre cei mai mari și mai rapizi furnizori de servicii de inferență AI și a început să implementeze mai mult de o mie de acceleratoare proprii, de dimensiunea unei farfurii, în America de Nord și în anumite părți ale Franței anunta The Register.
Urmărește cele mai noi producții video TechRider.ro
- articolul continuă mai jos -
Extinderea, confirmată la conferința HumanX AI din Las Vegas, include intenția Cerebras, de a construi noi centre de date în Texas, Minnesota, Oklahoma și Georgia până la sfârșitul acestui an, împreună cu primele sale facilități din Montreal, Canada și Franța.
Dintre aceste facilități, Cerebras va menține proprietatea deplină a site-urilor Oklahoma City și Montreal, în timp ce restul sunt operate în comun în baza unui acord cu finanțatorul emirat G42 Cloud.
Cea mai mare dintre facilitățile din SUA va fi situată în Minneapolis, Minnesota, și va avea 512 dintre acceleratoarele sale CS-3 AI, însumând 64 exaFLOPS de calcul FP16, când va fi online în al doilea trimestru al anului 2025.
Cerebras s-a poziționat ca un specialist în inferență de mare viteză, deoarece ei cred că raționamentul este următorul lucru important în dezvoltarea AI. Raționamentul face ca modelele AI să ruleze de 10 ori mai încet, deoarece modelul trebuie să gândească și să genereze o serie de monologuri interne înainte de a oferi răspunsul final. Această încetinire creează o oportunitate pentru Cerebras, al cărui hardware specializat este proiectat să accelereze aceste sarcini de lucru AI mai complexe.
Spre deosebire de multe dintre supercalculatoarele AI la scară largă și construirea centrelor de date anunțate în ultimul an, Cerebras va fi alimentat de acceleratoarele dezvoltate intern.
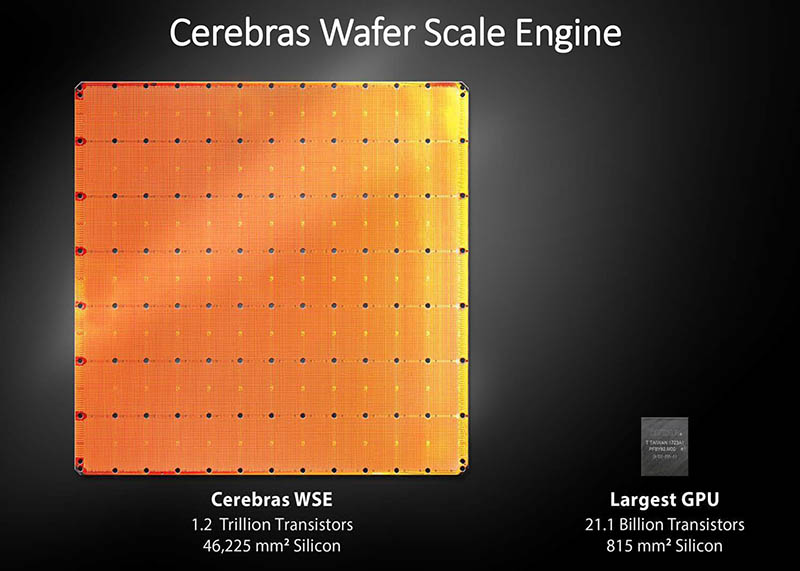
Anunțate acum un an, sistemele CS-3 de la Cerebras au un procesor la scară wafer care măsoară 46.225 mm2, care conține patru trilioane de tranzistori repartizați pe 900.000 de nuclee și dețin 44 GB de SRAM.
Acest sistem CS-3s este capabil să producă 125 petaFLOPS de performanță FP16 extrem de redusă, comparativ cu doar 2 petaFLOPS pe un H100 sau H200 și 5 petaFLOPS pe cele mai puternice GPU-uri Blackwell de la Nvidia.
Când CS-3 și-a făcut debutul, Cerebras era încă concentrat exclusiv pe antrenamentul de modele AI. Cu toate acestea, de atunci compania și-a extins oferta la inferență. Compania susține că poate servi Llama 3.1 70B cu până la 2.100 de tokene pe secundă.
Acest lucru este posibil, parțial, deoarece inferența modelului de limbă mare (LLM) este în primul rând legată de memorie și, în timp ce un singur CS-3 nu oferă prea mult în ceea ce privește capacitatea, compensează cu lățimea de bandă a memoriei oferite, care atinge vârful la 21 de petaocteți pe secundă. Un H100, pentru referință, oferă aproape dublul capacității de memorie, dar doar 3,35 TBps de lățime de bandă a memoriei. Cu toate acestea, numai acest lucru duce Cerebras la aproximativ 450 de tokene pe secundă.
Performanța rămasă este atinsă printr-o tehnică numită decodare speculativă, care utilizează un model AI mai mic pentru a genera rezultatul inițial, în timp ce un model AI mai mare acționează ca un verificator de fapte pentru a păstra acuratețea. Atâta timp cât proiectul de model nu face prea multe greșeli, îmbunătățirea performanței poate fi dramatică, până la o creștere de 6 ori a tokenelor pe secundă, potrivit unor rapoarte.
Cerebras se bazează foarte mult pe avantajul masiv al lățimii de bandă a acceleratorului său și pe experiența cu decodificarea speculativă pentru a se diferenția, mai ales pe măsură ce modelele „raționante” precum DeepSeek-R1 și QwQ devin mai comune.
Deoarece aceste modele se bazează pe raționamentul tip lanț de gândire, un răspuns ar putea necesita mii de tokene de „gândire” pentru a ajunge la un răspuns final, în funcție de complexitatea sa. Deci, cu cât poți produce mai repede tokene, cu atât oamenii rămân mai puțin timp în așteptarea unui răspuns și, probabil, cu atât mai mulți oameni sunt dispuși să plătească pentru privilegiul de utilizare a modelelor mari.
Desigur, cu doar 44 GB de memorie per accelerator, suportarea modelelor mai mari rămâne punctul dureros al lui Cerebras. Llama 3.3 70B, de exemplu, necesită cel puțin patru dintre CS-3 de la Cerebras pentru a rula la o precizie totală de 16 biți. Un model precum Llama 3.1 405B, pe care Cerebras l-a demonstrat, ar avea nevoie de mai mult de 20 pentru a rula cu o dimensiune de context semnificativă. Oricât de rapidă ar fi SRAM-ul lui Cerebras, compania este încă departe de a oferi modele la scară cu mai multe trilioane de parametri la orice viteză apropiată de viteza pe care o fac reclamă.
Acestea fiind spuse, viteza serviciului de inferență al Cerebras l-a ajutat deja să câștige contracte cu Mistral AI și, cel mai recent, Perplexity. Săptămâna aceasta, compania a anunțat încă o victorie a clienților cu platforma de informații de piață AlphaSense, intenționând să schimbe trei furnizori de modele cu sursă închisă pentru un model source care rulează pe CS-3-urile Cerebras.
Ca parte a dezvoltării infrastructurii, Cerebras își propune să extindă accesul API la acceleratoarele sale la mai mulți dezvoltatori printr-un acord cu populara platformă pentru dezvoltatori AI Hugging Face.
Serviciul de inferență Cerebras este acum disponibil ca parte a liniei de furnizori de inferență Hugging Face, care oferă acces la o varietate de furnizori de inferență ca serviciu, inclusiv SambaNova, TogetherAI, Replicate și alții, printr-o interfață comună și API.
Integrarea Hugging Face va permite celor cinci milioane de dezvoltatori ai săi să acceseze Cerebras Inference cu un singur clic, fără a fi nevoie să se înscrie la Cerebras separat. Acesta devine un canal de distribuție major pentru Cerebras, în special pentru dezvoltatorii care lucrează cu modele open-source precum Llama 3.3 70B.



