OpenAI a dezvăluit cea mai recentă serie de modele AI, GPT-4.1, care, contraintuitiv, este poziționată ca un succesor optimizat al GPT-4o, înlocuind GPT-4.5 experimental. De reținut este că GPT-4.1 va fi disponibil numai prin API și este un model non-reasoning, fără „gândire”. Intenția este să se renunțe la versiunea GPT-4.5 în API, deoarece GPT-4.1 oferă performanțe îmbunătățite sau similare pentru capabilități de coding, la un cost și o latență mult mai mici. Versiunea de previzualizare a GPT-4.5 va fi dezactivată în API în trei luni, pe 14 iulie 2025, pentru a oferi dezvoltatorilor timp să facă tranziția.
Urmărește cele mai noi producții video TechRider.ro
- articolul continuă mai jos -
API-ul este o interfață de programare pentru aplicații. Un API este un set de protocoale și instrucțiuni care determină modul în care două componente software comunică între ele. În cazul de față, API-ul OpenAI este interfața dintre modelul AI al companiei și diverse aplicații de programare asistată de AI, cum ar fi Cursor și Windsurf, sau webchat-uri independente.
Michelle Pokrass, responsabila de cercetare post-formare a OpenAI, a remarcat în transmisia live de lansare că „De fapt, decizia de a numi acest model 4.1 a fost intenționată”, iar Kevin Weil, CPO la OpenAI, a glumit: „Nu este doar faptul că stăm prost la denumiri.”
În timp ce OpenAI evidențiază scorul puternic de 90,2% al GPT-4.1 la benchmark-ul Massive Multitask Language Understanding (MMLU) – un test amplu care măsoară cunoștințele despre lume și soluționarea problemelor la zeci de subiecte – unde modelul Google are 84,1%, iar Claude 3.7 are 82,7%, GPT-4.1 pare totuși să fie în urma modelelor Google Gemini 2.5 Pro și Claude 3.7 de la Anthropic în segmente-cheie precum știința, raționamentul (cum ar fi GPQA) și codarea (cum ar fi SWE-Bench), deși modelele nu au fost puse în mod independent față în față în teste.
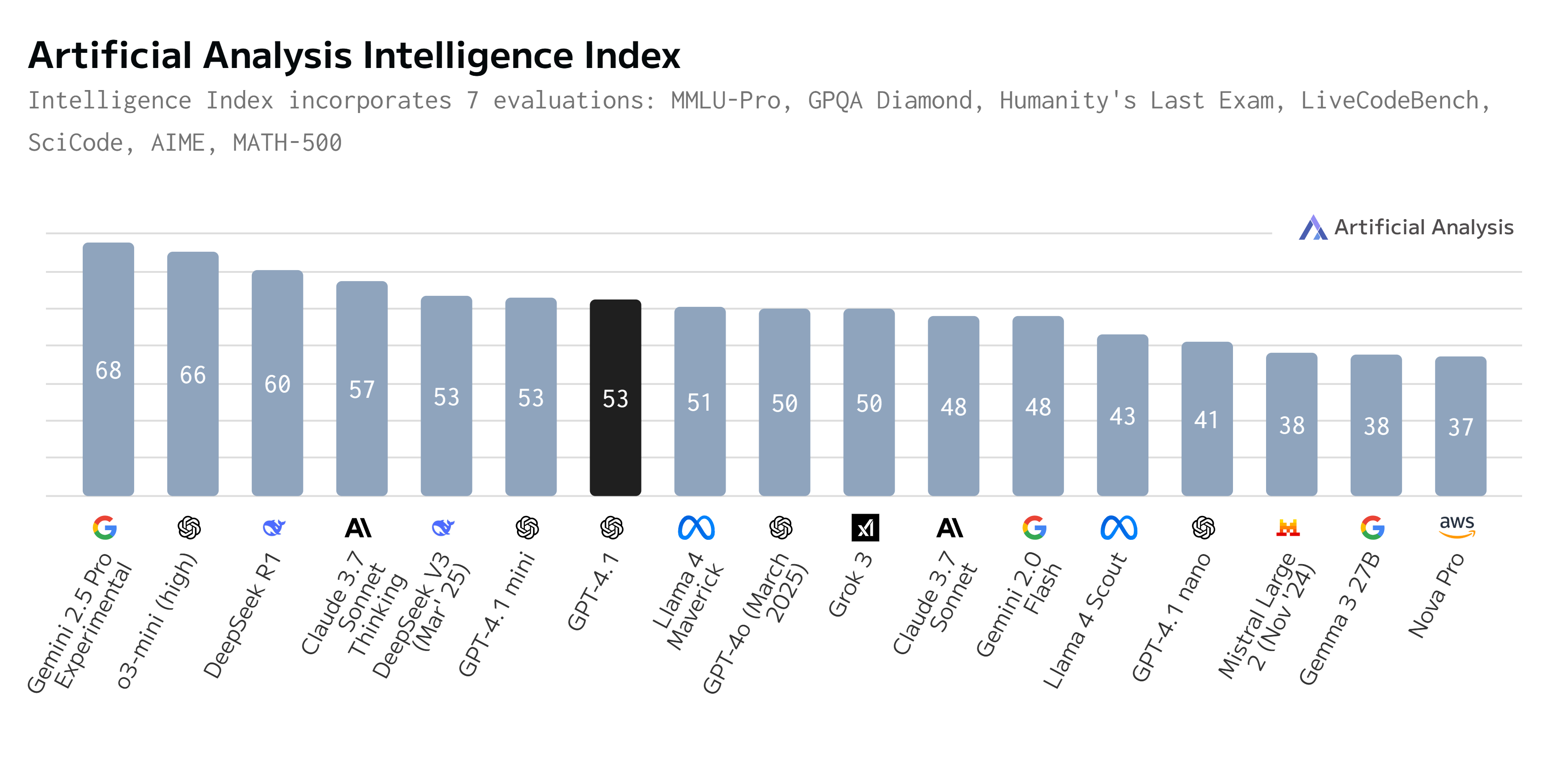
În sarcinile complexe de codare, de exemplu, GPT-4.1 a atins o precizie de doar 55% pe benchmark-ul verificat SWE-Bench, un salt mare față de 33% pentru GPT-4o. Totuși, acest scor se află în urma rezultatelor de top la același test SWE-Bench obținute de Google Gemini 2.5 Pro (63,8% cu instrumente agent) și Anthropic Claude 3.7 Sonnet (62–63%). În plus, în ceea ce privește știința și raționamentul avansat, cum ar fi GPQA (Graduate-Level Google-Proof Q&A), Google Gemini 2.5 Pro menține în prezent un avantaj mare, cu un scor de 84%, în timp ce GPT-4.1 a obținut un scor de 66,3%.
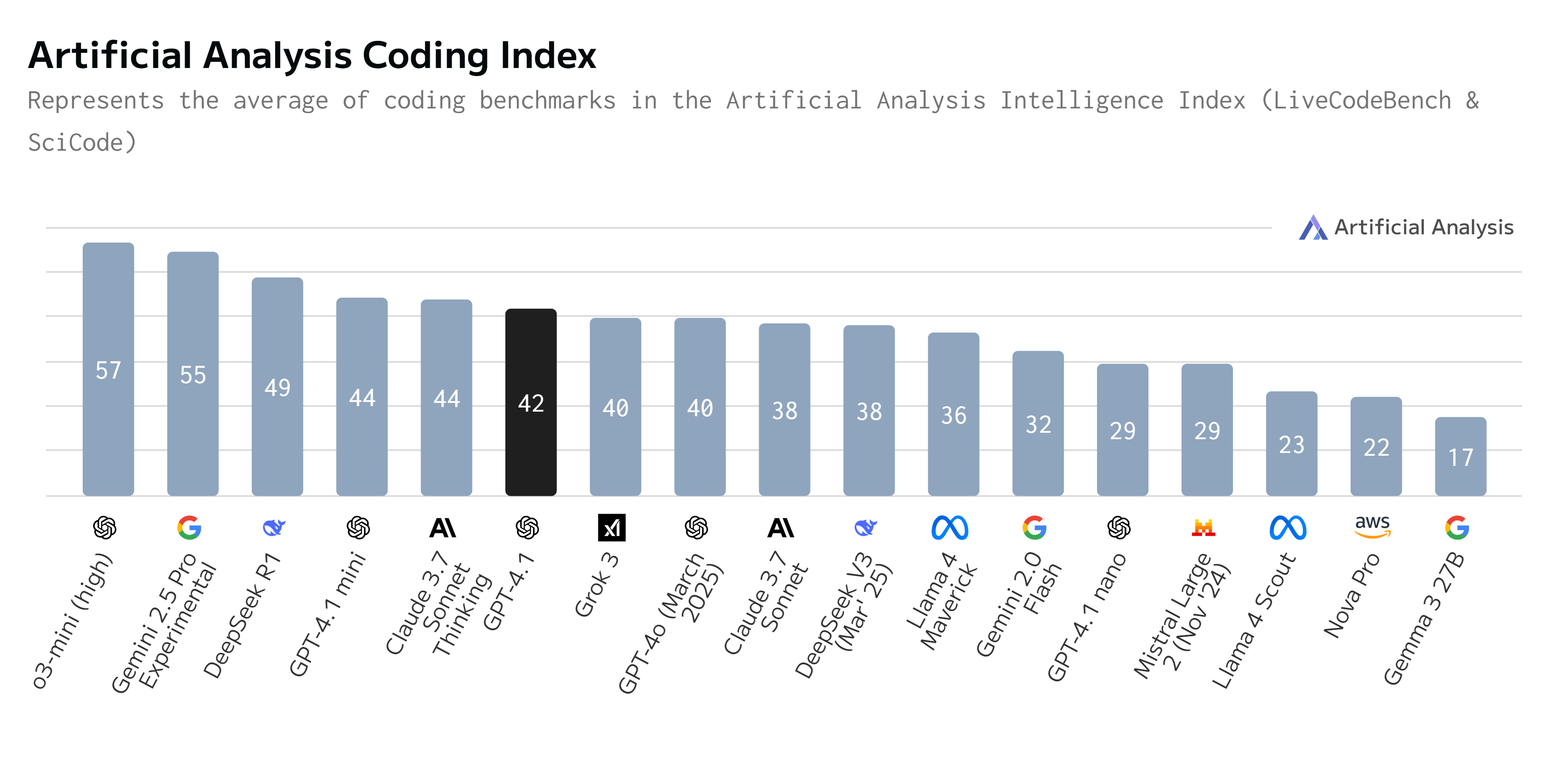
Pokrass a atribuit acest câștig în abilitățile de generare de cod colaborării apropiate cu dezvoltatorii, cu focus pe programare, declarând: „Am lucrat la capacitățile de programare ale modelului: să exploreze biblioteci de cod, să scrie teste unitare și să scrie cod pentru compilare.” Numele ales arată că această versiune nu s-a dorit a fi un pas revoluționar înainte ci doar o versiune dezvoltată cu un scop precis, dezvoltarea software.
Totuși, există nuanțe în performanța obținută, în funcție de sarcina specifică de codare. De exemplu, o analiză realizată de platforma de integritate a codului Qodo s-a concentrat în mod special pe generarea de sugestii de cod pentru cererile de extragere, mai degrabă decât pe sarcina mai largă SWE-Bench. GPT-4.1 a avut un ușor avantaj față de Claude 3.7 Sonnet în evaluarea sa. Qodo a remarcat că avantajul GPT-4.1 provine parțial dintr-o mai bună aderență la cerințele sarcinilor și furnizarea de sugestii mai relevante din punct de vedere contextual în scenarii specifice.
OpenAI poziționează GPT-4.1 drept „modelul central pentru trei dimensiuni: codare, urmărire a instrucțiunilor și context lung”, în eforturile sale de a-și păstra relevanța în dezvoltarea software, în fața competiției acerbe din partea Google și Anthropic.
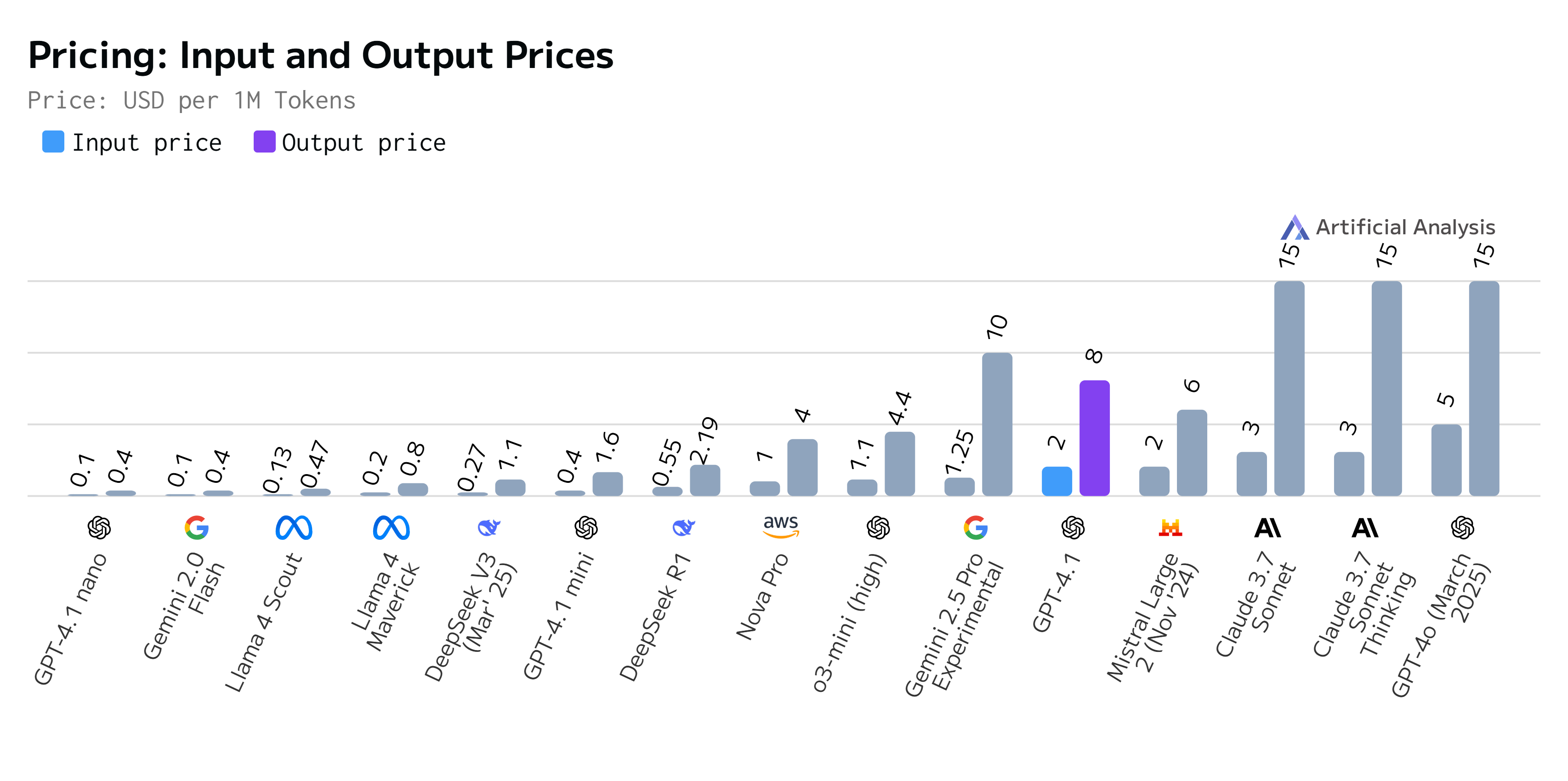
De asemenea, GPT-4.1 extinde semnificativ capacitățile de context ale OpenAI, încercând să ajungă modelul Google Gemini 2.5 Pro, cu o fereastră de context de 1 milion de jetoane – o creștere de opt ori față de limita de 128.000 de jetoane a GPT-4o anterior.
Această fereastră mai mare permite familiei de modele exclusiv pentru API (inclusiv noile versiuni mini și nano) să proceseze și să raționeze pe baza unor intrări extinse, cum ar fi „baze de coduri întregi”, documente lungi sau date multimodale complexe, cum ar fi videoclipurile. Alături de aceste îmbunătățiri tehnice, OpenAI a subliniat rentabilitatea; principalul model GPT-4.1 este cu 26% mai puțin costisitor decât GPT-4o prin API.
Dincolo de modelul principal GPT-4.1, OpenAI a introdus și GPT-4.1 mini și GPT-4.1 nano. Nano este poziționat ca un model rapid și ieftin pentru sarcini de bază, cum ar fi completarea automată sau clasificarea, oferind cea mai mică latență și cel mai mic cost (se pare că 12 cenți combinați per milion de jetoane) prin API. În ciuda dimensiunii și concentrării sale asupra vitezei, a atins totuși 80,1% din benchmark-ul MMLU. Versiunea mini, între timp, oferă un echilibru: un nivel ridicat de inteligență și cunoștințe, combinat cu un preț redus și o viteză mai bună decât modelul de bază, fiind concepută ca modelul de top pentru procesarea multimodală sau a imaginilor.
Pivotul strategic al OpenAI către un model mai eficient reflectă decizia sa de a renunța treptat la versiunea de previzualizare GPT-4.5, care consumă foarte multe resurse de calcul.
Lansarea lui GPT-4.1 este un moment important pentru OpenAI. Echilibrează capacitățile multimodale competitive și procesarea în context larg la un preț mai mic, în contextul intensificării concurenței din partea Anthropic și Google, care avansează rapid. Între timp, diferențele dintre modelele de top sunt tot mai mici, pe măsură ce cursa AI continuă să se intensifice. Gemini 2.5 Pro, de exemplu, a primit aclamații pozitive pe scară largă pe rețelele de socializare în ultimele săptămâni, în special pentru priceperea sa în programare.
ChatGPT-4.1 este conceput pentru dezvoltatori, oferind acces exclusiv prin API, care ajută la integrarea perfectă în diverse aplicații. Capacitățile sale sunt potrivite pentru construirea de sisteme agentice și îmbunătățirea utilizării instrumentelor, făcându-l o resursă valoroasă pentru echipele tehnice. Concentrându-se pe nevoile dezvoltatorilor, OpenAI vrea să se asigure că GPT-4.1, deși nu reușește să depășească principalii competitori, rămâne un instrument practic și eficient pentru o gamă largă de proiecte de dezvoltare software.