LLM-urile au atins un nou minim la ARC-AGI-2 Benchmark. ARC Prize, o organizație non-profit care evaluează eficacitatea modelelor AI pentru a demonstra inteligența umană, a anunțat noul test referința ARC-AGI-2.
Urmărește cele mai noi producții video TechRider.ro
- articolul continuă mai jos -
Noul benchmark este un succesor al benchmark-ului ARC-AGI lansat cu câțiva ani în urmă. La fel ca și predecesorul său, benchmark-ul testează modele AI pe sarcini care sunt modele relativ ușoare pentru oameni, dar dificile pentru sistemele artificiale.
Benchmark-ul ARC-AGI-2 prezintă provocări și mai mari decât predecesorul său, deoarece ține cont de eficiență (cost-pe-sarcină) pe lângă performanță. Sarcinile necesită ca modelele AI să interpreteze simbolurile dincolo de tiparele lor vizuale, să aplice simultan reguli interconectate și să utilizeze reguli diferite în funcție de context.
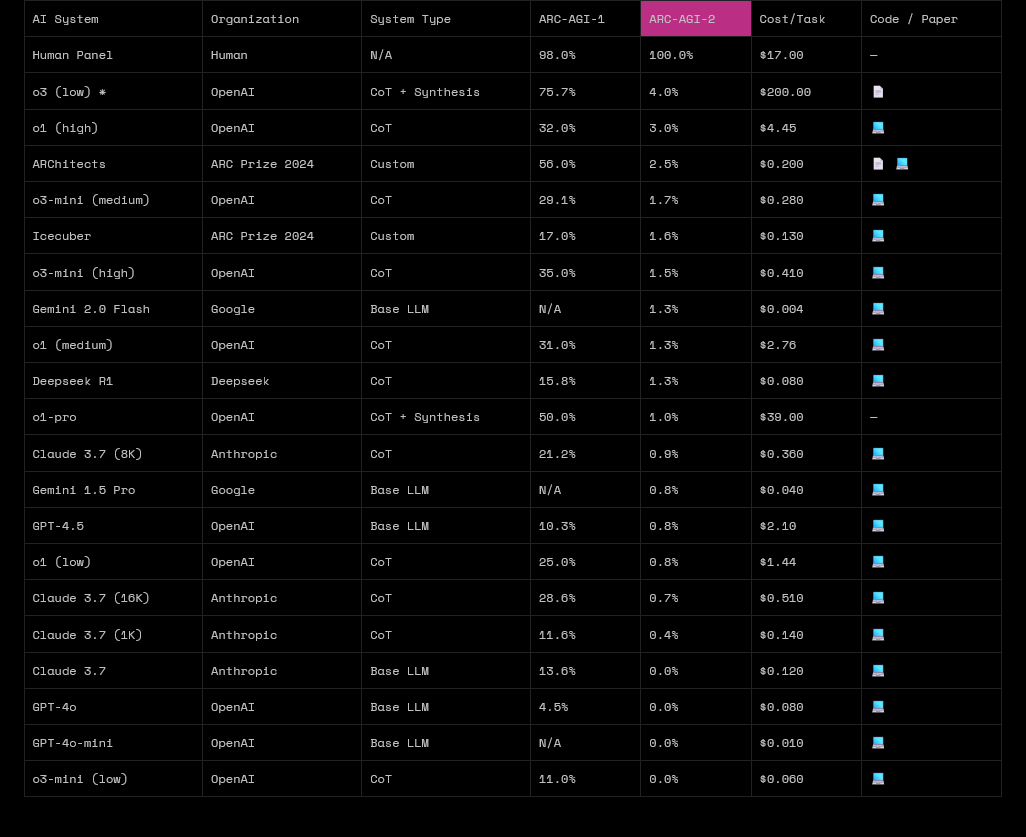
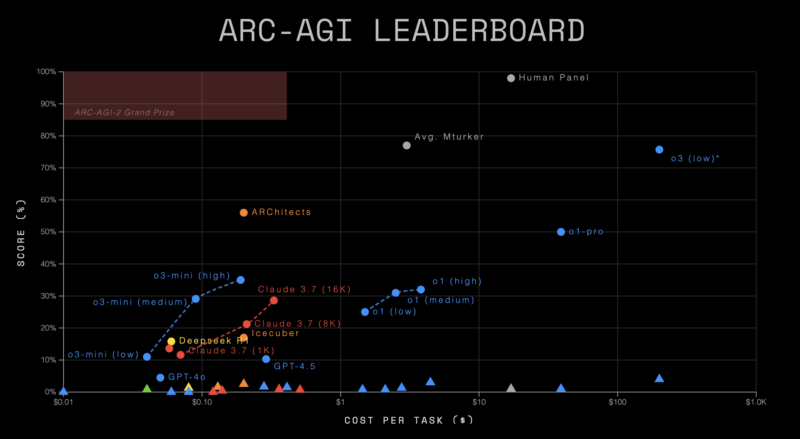
Rezultatele au arătat că modelele AI au găsit toate sarcinile de mai sus dificile. Modelele fără raționament, sau „LLM-uri pure”, au obținut un scor de 0% la benchmark, în timp ce alte modele cu raționament disponibile public au primit scoruri procentuale cu o singură cifră de mai puțin de 4%. În schimb, un panou uman care rezolva sarcinile a obținut un scor perfect de 100%.
„Sistemele AI sunt deja supraomenești în multe domenii specifice (de exemplu, jocul Go și recunoașterea imaginii.) Cu toate acestea, acestea sunt capacități înguste, specializate. „Decalajul uman-ai” dezvăluie ceea ce lipsește pentru inteligența generală AGI – dobândirea de noi abilități în mod eficient”, a spus organizația.
Modelul de raționament O3 nelansat al OpenAI a obținut cel mai mare scor de 4,0%. În precedentul benchmark ARC-AGI-1, a obținut 75,7%. Cu toate acestea, Sam Altman, CEO al OpenAI, a dezvăluit că acesta nu va fi lansat ca model independent. În schimb, capacitățile de raționament ale lui o3 vor fi integrate într-un model hibrid GPT-5.
În plus, nu au existat scoruri demne de remarcat de la alte modele AI. Chiar și modelul Claude 3.7 Sonnet lansat recent, adesea considerat cel mai bun model pentru codare, a obținut un scor de 0,7%, în timp ce modelul DeepSeek-R1 a obținut un scor de 1,3%. Clasamentul a subliniat, de asemenea, costul (în USD) suportat pentru îndeplinirea fiecărei sarcini.
„Toate celelalte criterii de referință AI se concentrează pe capacități supraumane sau cunoștințe specializate prin testarea abilităților” PhD++ „. ARC-AGI este singurul test de referință care abordează un strategie opusă, concentrându-se pe sarcini care sunt relativ ușoare pentru oameni, dar dificile sau imposibile pentru AI”, a adăugat organizația.
François Chollet, creatorul Keras și fost cercetător Google, este unul dintre creatorii benchmark-ului ARC-AGI. El a spus că este „singurul punct de referință AI care măsoară progresul către inteligența generală”.
Recent, Chollet, împreună cu co-fondatorul Zapier, Mike Knoop, au lansat Ndea, un nou laborator de cercetare dedicat creării inteligenței generale artificiale (AGI).
Raționamentul complex necesită o înțelegere mai profundă a informațiilor, nu doar repetarea stocastică, adică o aplicare a calculului probabilităților la rezultatele obținute prin statistică. În mare parte, printr-o simplificare forțată, aceasta este metoda aflata la baza construirii si antrenării modelelor AI. Acestea reușesc sa obțină rezultatele excepționale din prezent doar prin ingurgitarea unor cantități masive de date în procesul de training/antrenare. Însă acuratețea rezultatelor oferite de modelele AI actuale încă nu este la nivelul dorit. Arhitecturile simbolice vectoriale ne-ar putea apropia, dar până când vom reuși să modelăm complet procesele cognitive în cod, aceasta va continua să fie norma.
Clasamentul ARC-AGI-2 care poate fi explorat aici: